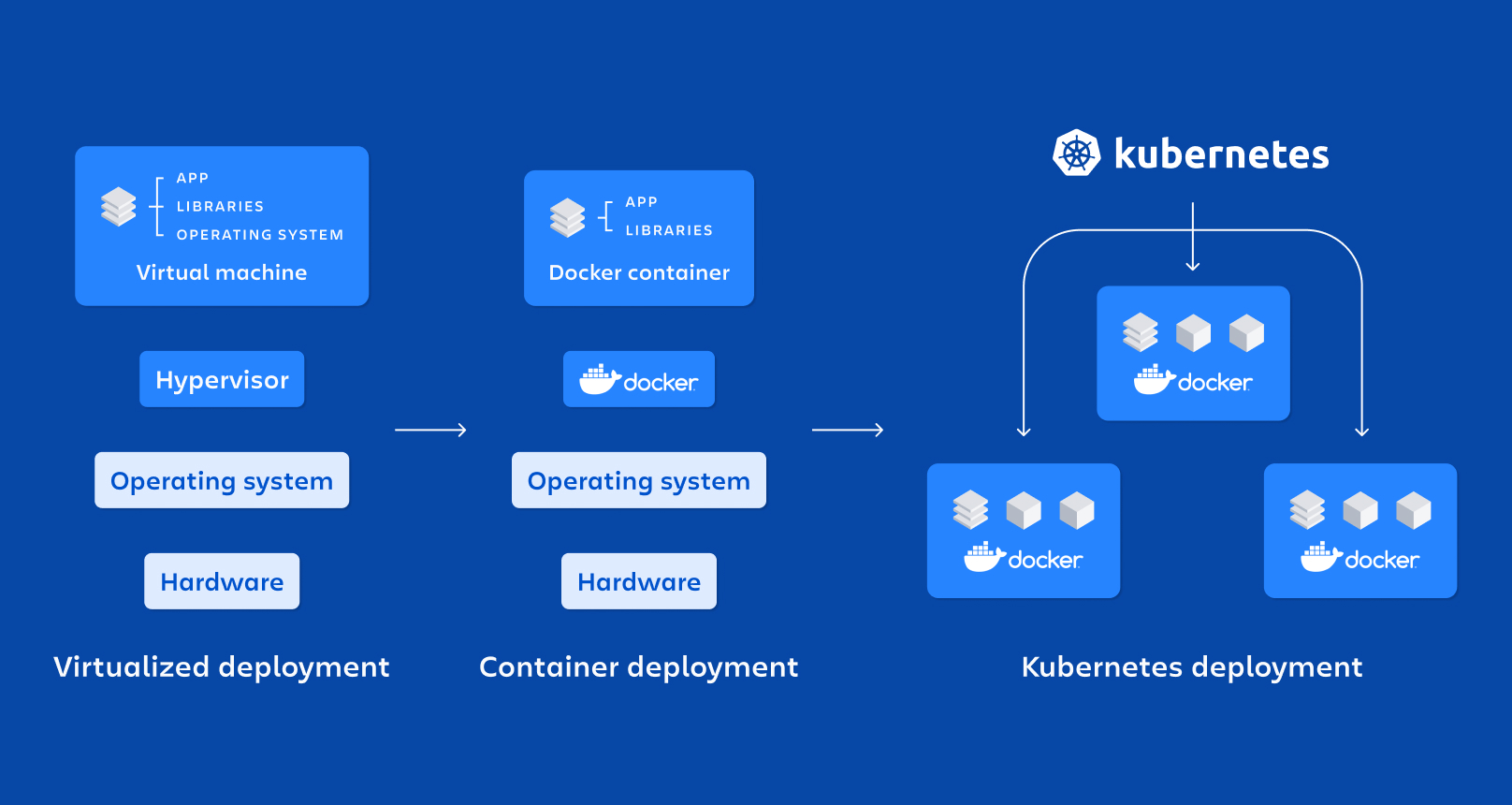
Kubernetes Step by Step Install
Step by Step approach for install master node
Warning
This is only for experienced user who interested to explore the detail of use kubeadm to install master node.
from azure shell , create alias for ssh into master and worker node.
create some script
echo 'ssh_worker_function() {
cd $HOME/k8s-101-workshop/terraform/
nodename=$(terraform output -json | jq -r .linuxvm_worker_FQDN.value)
username=$(terraform output -json | jq -r .linuxvm_username.value)
ssh -o "StrictHostKeyChecking=no" $username@$nodename
}
alias ssh_worker="ssh_worker_function"' >> $HOME/.bashrc
echo 'ssh_master_function() {
cd $HOME/k8s-101-workshop/terraform/
nodename=$(terraform output -json | jq -r .linuxvm_master_FQDN.value)
username=$(terraform output -json | jq -r .linuxvm_username.value)
export fqdn=${nodename}
ssh -o "StrictHostKeyChecking=no" -t $username@$nodename "export fqdn=${fqdn}; exec bash"
}
alias ssh_master="ssh_master_function"' >> $HOME/.bashrc
alias k='kubectl' >> $HOME/.bashrc
source $HOME/.bashrc
generate ssh-key for master and worker node
- clean existing kubeconfig
rm -f /home/$(whoami)/.ssh/known_hosts
- get the password for VM
the password will be needed when use ssh-copy-id to copy ssh key into the master node.
cd $HOME/k8s-101-workshop/terraform/
terraform output -json | jq -r .linuxvm_password.value
echo $vmpassword
- generate ssh-key
if key exist, choose either Overwrite or not.
[ ! -f ~/.ssh/id_rsa ] && ssh-keygen -q -N "" -f ~/.ssh/id_rsa
- copy ssh-key to master node, enter password when prompted.
cd $HOME/k8s-101-workshop/terraform/
nodename=$(terraform output -json | jq -r .linuxvm_master_FQDN.value)
username=$(terraform output -json | jq -r .linuxvm_username.value)
ssh-copy-id -f -o 'StrictHostKeyChecking=no' $username@$nodename
- copy ssh-key to worker node, enter password when prompted.
cd $HOME/k8s-101-workshop/terraform/
nodename=$(terraform output -json | jq -r .linuxvm_worker_FQDN.value)
username=$(terraform output -json | jq -r .linuxvm_username.value)
ssh-copy-id -f -o 'StrictHostKeyChecking=no' $username@$nodename
after done above, you shall able to use alias ssh_master and ssh_worker to ssh into worker node and master node.
use alias ssh_master to ssh into master node. below all config are done on master node.
sudo apt-get update -y
sudo apt-get install socat conntrack -y
sudo apt-get install jq -y
sudo apt-get install apt-transport-https ca-certificates -y
sudo apt-get install hey -y
Setting Kernel Parameters for k8s
- install kernel dep module for cri-o runtime
overlay: Docker and CRI-O can use it to efficiently manage container images and layers
br_netfilter: This module is required for network packet filtering, bridging, and IP masquerading, which are essential for Kubernetes networking. It allows the Linux kernel’s netfilter to process bridged (Layer 2) traffic.
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
- enable iptables support for bridge and enable ip_forwarding
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
Install CRI-O
Configure the CRI-O repository:
First, add the CRI-O repository. Ensure you replace <VERSION> with the version of Kubernetes you intend to use, for example, 1.25:
OS="xUbuntu_22.04"
VERSION="1.27"
echo "deb [signed-by=/usr/share/keyrings/libcontainers-archive-keyring.gpg] https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/ /" | sudo tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable.list
echo "deb [signed-by=/usr/share/keyrings/libcontainers-crio-archive-keyring.gpg] https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable:/cri-o:/$VERSION/$OS/ /" | sudo tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable:cri-o:$VERSION.list
- Add the GPG key
mkdir -p /usr/share/keyrings
sudo curl -L --retry 3 --retry-delay 5 https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/Release.key | sudo gpg --dearmor -o /usr/share/keyrings/libcontainers-archive-keyring.gpg.tmp
sudo mv -f /usr/share/keyrings/libcontainers-archive-keyring.gpg.tmp /usr/share/keyrings/libcontainers-archive-keyring.gpg
sudo curl -L --retry 3 --retry-delay 5 https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable:/cri-o:/$VERSION/$OS/Release.key | sudo gpg --dearmor -o /usr/share/keyrings/libcontainers-crio-archive-keyring.gpg.tmp
sudo mv -f /usr/share/keyrings/libcontainers-crio-archive-keyring.gpg.tmp /usr/share/keyrings/libcontainers-crio-archive-keyring.gpg
- Install CRI-O
CRI-O is an open-source container runtime specifically designed for Kubernetes. It implements the Kubernetes Container Runtime Interface (CRI), allowing Kubernetes to use any OCI (Open Container Initiative)-compliant runtime as the container runtime for running pods. all Docker image are OCI-compliant.
CRI-O-Runc is a CLI tool for spawning and running containers according to the OCI specification.
sudo apt-get update
sudo apt-get install cri-o cri-o-runc -y
- Start and enable CRI-O
sudo systemctl daemon-reload
sudo systemctl enable crio
sudo systemctl start crio
After this step, you can optionaly use
journalctl -f -u crio to check the running status of crio, you shall see error message related with CNI which is normal, because we have not installed any CNI yet
Install crictl
install crictl which is the client tool for interactive with crio.
DOWNLOAD_DIR="/usr/local/bin"
sudo mkdir -p "$DOWNLOAD_DIR"
CRICTL_VERSION="v1.27.1"
ARCH="amd64"
curl --insecure --retry 3 --retry-connrefused -fL "https://github.com/kubernetes-sigs/cri-tools/releases/download/$CRICTL_VERSION/crictl-$CRICTL_VERSION-linux-$ARCH.tar.gz" | sudo tar -C $DOWNLOAD_DIR -xz
After this step, you can optionaly use sudo crictl info to check the status of crio. it shall tell you the container runtime is ready, but the network status is not ready.
Install kubeadm, kubelet and kubectl
kubeadm is the binary that responsible for k8s installation, kubelet is the agent(binary) on each worker node to take the instruction from kube-apiserver and then talk to CRI-O with CRI standard to manage life-cycle of container. kubectl is the client that talk to k8s API server for daily k8s operation.
Below script downloading specific versions of kubeadm, kubelet, and kubectl, placing them in the system path, configuring kubelet to run as a systemd service, and ensuring it starts automatically.
Download 1.27.1 version kubeadm and kubelet
#RELEASE="$(curl -sSL https://dl.k8s.io/release/stable.txt)"
RELEASE="v1.27.1"
ARCH="amd64"
DOWNLOAD_DIR="/usr/local/bin"
sudo mkdir -p "$DOWNLOAD_DIR"
cd $DOWNLOAD_DIR
sudo curl --insecure --retry 3 --retry-connrefused -fL --remote-name-all https://dl.k8s.io/release/$RELEASE/bin/linux/$ARCH/{kubeadm,kubelet}
sudo chmod +x {kubeadm,kubelet}
Download service file for start kubelet and kubeadm, kubeadm use system service to manage kubelet.
RELEASE_VERSION="v0.4.0"
curl --insecure --retry 3 --retry-connrefused -fL "https://raw.githubusercontent.com/kubernetes/release/$RELEASE_VERSION/cmd/kubepkg/templates/latest/deb/kubelet/lib/systemd/system/kubelet.service" | sed "s:/usr/bin:$DOWNLOAD_DIR:g" | sudo tee /etc/systemd/system/kubelet.service
sudo mkdir -p /etc/systemd/system/kubelet.service.d
sudo curl --insecure --retry 3 --retry-connrefused -fL "https://raw.githubusercontent.com/kubernetes/release/$RELEASE_VERSION/cmd/kubepkg/templates/latest/deb/kubeadm/10-kubeadm.conf" | sed "s:/usr/bin:$DOWNLOAD_DIR:g" | sudo tee /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
Download kubectl.
KUBECTL_VERSION="v1.28.1"
sudo curl --insecure --retry 3 --retry-connrefused -fLO https://dl.k8s.io/release/$KUBECTL_VERSION/bin/linux/$ARCH/kubectl
sudo cp kubectl /usr/local/bin
sudo chmod +x /usr/local/bin/kubectl
Enabling and Starting kubelet
sudo systemctl enable --now kubelet
Use kubeadm to initial Installation
Pulling Kubernetes Container Images
kubeadm will pull the core component of k8s, which are
-kube-apiserver
-kube-controller-manager
-kube-scehduler
-kube-proxy
-pause
-etcd
-coredns
sudo kubeadm config images pull --cri-socket unix:///var/run/crio/crio.sock --kubernetes-version=$RELEASE --v=5
Config kubeadm init parameters
Kubeadm require some parameter to initionize the installation which include NODEIP, cluster-dns, POD_CIDR, SERVICE_CIDR, also certificate parameter like sans etc., kubeadm will also create a token for worker node to join.
CLUSTERDNSIP must in range of SERVICE_CIDR. the ${fqdn} will be required if kubectl use fqdn of API_SERVER to use Kubernetes API.
when use alias ssh_master to ssh into the master node, the fqdn already set to actual domain name of the master node VM, if not, you must set fqdn byself, for example , fqnd=k8sXX-master.eastus.cloudapp.azure.com
local_ip=$(ip route get 8.8.8.8 | awk -F"src " 'NR==1{split($2,a," ");print a[1]}')
CLUSTERDNSIP="10.96.0.10"
cat <<EOF | sudo tee /etc/default/kubelet
KUBELET_EXTRA_ARGS=--node-ip=$local_ip,--cluster-dns=$CLUSTERDNSIP
EOF
IPADDR=$local_ip
NODENAME=`hostname | tr -d '-'`
POD_CIDR="10.244.0.0/16"
SERVICE_CIDR="10.96.0.0/12"
echo $IPADDR $NODENAME | sudo tee -a /etc/hosts
Initializing the Kubernetes Cluster
sudo kubeadm reset -f
sudo kubeadm init --cri-socket=unix:///var/run/crio/crio.sock --apiserver-advertise-address=$IPADDR --apiserver-cert-extra-sans=$IPADDR,${fqdn} --service-cidr=$SERVICE_CIDR --pod-network-cidr=$POD_CIDR --node-name $NODENAME --token-ttl=0 -v=5
Configuring kubectl for the Current User and Root
after done the kubeadm installation, a kubeconfig file will be created which include the certificate for kubectl client to use to talk to kube-api server.
mkdir -p /home/ubuntu/.kube
sudo cp -f /etc/kubernetes/admin.conf /home/ubuntu/.kube/config
sudo chown ubuntu:ubuntu /home/ubuntu/.kube/config
sudo mkdir -p /root/.kube
sudo cp -f /home/ubuntu/.kube/config /root/.kube/config
kubectl --kubeconfig /home/ubuntu/.kube/config config set-cluster kubernetes --server "https://$fqdn:6443"
Install Calico CNI
The default bridge CNI in Kubernetes does not support cross-node networking. To enable this capability, We diretly install Calico CNI, Calico uses VXLAN technology to facilitate network expansion across multiple nodes, providing enhanced networking features.
Calico CNI extends standard Kubernetes API with its own API definitions, allowing for advanced network configurations. The installation and management of Calico are streamlined through the use of tigera-operator.yaml and custom-resources.yaml. The Tigera Operator automates Calico’s lifecycle management, while custom-resources.yaml enables administrators to tailor Calico’s configuration to the specific needs of their Kubernetes cluster.
The configuration below includes enabling IP forwarding for containers. Typically, this setting is not necessary unless the container acts as a Layer 3 router, involving multiple IP interfaces. In this setup, BGP is disabled because we utilize VXLAN for networking, which does not require direct exchange of Pod IPs across nodes.
This approach ensures that Calico provides robust and flexible networking capabilities for Kubernetes clusters, supporting a wide range of deployment scenarios, including those requiring cross-node networking and advanced network routing features.
cd $HOME
#sudo curl --insecure --retry 3 --retry-connrefused -fL https://github.com/projectcalico/calico/releases/latest/download/calicoctl-linux-amd64 -o /usr/local/bin/calicoctl
sudo curl --insecure --retry 3 --retry-connrefused -fL https://github.com/projectcalico/calico/releases/download/v3.25.0/calicoctl-linux-amd64 -o /usr/local/bin/calicoctl
sudo chmod +x /usr/local/bin/calicoctl
curl --insecure --retry 3 --retry-connrefused -fLO https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/tigera-operator.yaml
kubectl --kubeconfig /home/ubuntu/.kube/config create -f tigera-operator.yaml
kubectl rollout status deployment tigera-operator -n tigera-operator
curl --insecure --retry 3 --retry-connrefused -fLO https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/custom-resources.yaml
sed -i -e "s?blockSize: 26?blockSize: 24?g" custom-resources.yaml
sed -i -e "s?VXLANCrossSubnet?VXLAN?g" custom-resources.yaml
sed -i -e "s?192.168.0.0/16?$POD_CIDR?g" custom-resources.yaml
#sed -i -e "s?192.168.0.0/16?10.244.0.0/16?g" custom-resources.yaml
sed -i '/calicoNetwork:/a\ containerIPForwarding: Enabled ' custom-resources.yaml
sed -i '/calicoNetwork:/a\ bgp: Disabled ' custom-resources.yaml
kubectl --kubeconfig /home/ubuntu/.kube/config create namespace calico-system
sleep 1
kubectl get namespace calico-system
kubectl --kubeconfig /home/ubuntu/.kube/config apply -f custom-resources.yaml
sleep 5
kubectl rollout status deployment calico-kube-controllers -n calico-system
kubectl rollout status ds calico-node -n calico-system
use sudo calicoctl node status to check calico node status, until it show calico process is running
use kubectl get tigerastatus to check calico status via calico extended api
expected output from watch kubectl get tigerastatus
until both AVAILABLE to “True”
expected outcome
apiserver True False False 68s
calico True False False 83s
create token for other worker node to join
create a new token for worker node to join
on master node do
kubeadm token create --print-join-command > /home/ubuntu/workloadtojoin.sh
kubeadm config print join-defaults > /home/ubuntu/kubeadm-join.default.yaml
echo '#sudo kubeadm join --config kubeadm-join.default.yaml' | sudo tee -a /home/ubuntu/workloadtojoin.sh
chmod +x /home/ubuntu/workloadtojoin.sh
cat /home/ubuntu/workloadtojoin.sh
then exit the master node, back to az shell.
install worker node
To configure the worker nodes in your Kubernetes cluster, you need to install specific components that manage the container lifecycle and networking. Each worker node requires the installation of kubelet and cri-o for container management, as well as kube-proxy to set up iptables rules for service-to-container communication.
Since the commands for installing these components on the worker nodes overlap with those covered in the “Install Master Node” section, this guide will focus on providing a streamlined, “simple way” to set up each worker node. This method allows for a quick and efficient installation by copying and pasting the script below directly into the terminal of each worker node.
ssh into your workder node use alias ssh_worker
and Execute the Installation Script by copy and paste the following script into the terminal of the worker node to start the installation process: We are not going to explain each step for install worker node as those are just part of install master node.
#!/bin/bash -xe
error_handler() {
echo -e "\e[31mAn error occurred. Exiting...\e[0m" >&2
tput bel
}
trap error_handler ERR
sudo kubeadm reset -f
cd $HOME
sudo apt-get update -y
sudo apt-get install socat conntrack -y
sudo apt-get install jq -y
sudo apt-get install apt-transport-https ca-certificates -y
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
OS="xUbuntu_22.04"
VERSION="1.27"
echo "deb [signed-by=/usr/share/keyrings/libcontainers-archive-keyring.gpg] https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/ /" | sudo tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable.list
echo "deb [signed-by=/usr/share/keyrings/libcontainers-crio-archive-keyring.gpg] https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable:/cri-o:/$VERSION/$OS/ /" | sudo tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable:cri-o:$VERSION.list
mkdir -p /usr/share/keyrings
sudo curl -L --retry 3 --retry-delay 5 https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/Release.key | sudo gpg --dearmor -o /usr/share/keyrings/libcontainers-archive-keyring.gpg.tmp
sudo mv -f /usr/share/keyrings/libcontainers-archive-keyring.gpg.tmp /usr/share/keyrings/libcontainers-archive-keyring.gpg
sudo curl -L --retry 3 --retry-delay 5 https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable:/cri-o:/$VERSION/$OS/Release.key | sudo gpg --dearmor -o /usr/share/keyrings/libcontainers-crio-archive-keyring.gpg.tmp
sudo mv -f /usr/share/keyrings/libcontainers-crio-archive-keyring.gpg.tmp /usr/share/keyrings/libcontainers-crio-archive-keyring.gpg
sudo apt-get update
sudo apt-get install cri-o cri-o-runc -y
sudo systemctl daemon-reload
sudo systemctl enable crio
sudo systemctl start crio
DOWNLOAD_DIR="/usr/local/bin"
sudo mkdir -p "$DOWNLOAD_DIR"
CRICTL_VERSION="v1.27.1"
ARCH="amd64"
curl --insecure --retry 3 --retry-connrefused -fL "https://github.com/kubernetes-sigs/cri-tools/releases/download/$CRICTL_VERSION/crictl-$CRICTL_VERSION-linux-$ARCH.tar.gz" | sudo tar -C $DOWNLOAD_DIR -xz
#RELEASE="$(curl -sSL https://dl.k8s.io/release/stable.txt)"
RELEASE="v1.27.1"
ARCH="amd64"
DOWNLOAD_DIR="/usr/local/bin"
sudo mkdir -p "$DOWNLOAD_DIR"
cd $DOWNLOAD_DIR
sudo curl --insecure --retry 3 --retry-connrefused -fL --remote-name-all https://dl.k8s.io/release/$RELEASE/bin/linux/$ARCH/{kubeadm,kubelet}
sudo chmod +x {kubeadm,kubelet}
RELEASE_VERSION="v0.4.0"
curl --insecure --retry 3 --retry-connrefused -fL "https://raw.githubusercontent.com/kubernetes/release/$RELEASE_VERSION/cmd/kubepkg/templates/latest/deb/kubelet/lib/systemd/system/kubelet.service" | sed "s:/usr/bin:$DOWNLOAD_DIR:g" | sudo tee /etc/systemd/system/kubelet.service
sudo mkdir -p /etc/systemd/system/kubelet.service.d
sudo curl --insecure --retry 3 --retry-connrefused -fL "https://raw.githubusercontent.com/kubernetes/release/$RELEASE_VERSION/cmd/kubepkg/templates/latest/deb/kubeadm/10-kubeadm.conf" | sed "s:/usr/bin:$DOWNLOAD_DIR:g" | sudo tee /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
sudo mkdir -p /etc/kubernetes/manifests
KUBECTL_VERSION="v1.28.1"
sudo curl --insecure --retry 3 --retry-connrefused -fLO https://dl.k8s.io/release/$KUBECTL_VERSION/bin/linux/$ARCH/kubectl
sudo chmod +x /usr/local/bin/kubectl
sudo systemctl enable --now kubelet
cd $HOME
[ $? -eq 0 ] && echo "installation done"
trap - ERR
then exit the worker node back to az shell
Joining a Worker Node to the Cluster
Now that we have everything set up, it’s time to join the worker node to the cluster. This process involves using a token for joining, as well as the hash of the master node’s CA certificate for authentication purposes. This ensures the worker node is joining the intended Kubernetes cluster.
Retrieve the Join Command from master node
Once logged into the master node via ssh_master from azure shell, use the following command to display the join token and CA certificate hash. This information is stored in the workloadtojoin.sh file:
cat /home/ubuntu/workloadtojoin.sh
Copy the content displayed by the cat command.
After copying the necessary join command, exit the master node session.
SSH into the Worker Node with alias ssh_worker to join the worker node to Cluster
On the worker node, paste the previously copied join command to connect the worker node to the Kubernetes cluster. Replace , Replace and with the actual token and hash values you copied earlier. This command requires sudo to ensure it has the necessary permissions:
sudo kubeadm join <master node ip>:6443 --token <paste your token here> --discovery-token-ca-cert-hash <paste your hash here>
If there’s a need to reset the Kubernetes setup on the worker node before joining, you can use sudo kubeadm reset -f. This step is generally only necessary if you’re reconfiguring or troubleshooting the node
Following these steps will successfully join your worker node to the Kubernetes cluster. You can repeat the process for multiple worker nodes to expand the cluster’s capacity for running workloads.
then exit the worker node and ssh_master into the master node to check cluster node status
you are expected to see both master node and worker node shall in Ready status.
expected outcome
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node-worker Ready <none> 54s v1.27.1 10.0.0.4 <none> Ubuntu 22.04.5 LTS 6.5.0-1025-azure cri-o://1.27.4
nodemaster Ready control-plane 10m v1.27.1 10.0.0.5 <none> Ubuntu 22.04.5 LTS 6.5.0-1025-azure cri-o://1.27.4
After Successfully Joining Worker Nodes to the Cluster
Once you have successfully joined the worker nodes to the cluster, return to the master node to continue the setup or deployment process. Use the SSH command provided earlier to access the master node and proceed with your Kubernetes configuration or application deployment.
prepare access Kubernetes on azure shell
copy kubectl configuration to azure shell to use kubenetnes. as azure shell is outside for azure VM VPC, so it’s required to use Kubernetes master node public ip to access it.
cd $HOME/k8s-101-workshop/terraform/
nodename=$(terraform output -json | jq -r .linuxvm_master_FQDN.value)
username=$(terraform output -json | jq -r .linuxvm_username.value)
rm -rf $HOME/.kube/
mkdir -p ~/.kube/
scp -o 'StrictHostKeyChecking=no' $username@$nodename:~/.kube/config $HOME/.kube
sed -i "s|server: https://[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}:6443|server: https://$nodename:6443|" $HOME/.kube/config
Verify the installation is sucessful
from azure cloud shell.
run
expected result.
NAME STATUS ROLES AGE VERSION
node-worker Ready <none> 5h36m v1.27.1
nodemaster Ready control-plane 5h49m v1.27.1
Review Questions
- Try to use flannel instead calico as CNI
- Try to replace CRI-O with Docker as container runtime
- List all the k8s component that installed on master node and worker node.